Es un algoritmo muy similar al anterior, la diferencia fundamental es la siguiente:
Cada individuo generado se enfrenta al conjunto de datos, luego se muta y se vuelve a enfrentar al conjunto de datos. Si esa mutación mejora la aproximación se queda, caso contrario se restauran los coeficientes anteriores. Lo primero que se observa es que, al haber un nuevo proceso, este algoritmo es más lento que el anterior. Sin embargo, durante las pruebas se muestra una mejora en el ajuste.
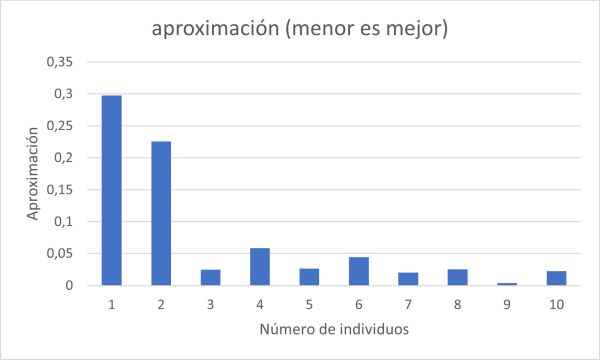
Resultado de una prueba de ejemplo
Se genera un conjunto de datos de 2000 registros (X, Y) y se ejecuta el algoritmo genético para hallar una sola función que cubra todo el conjunto de datos, luego con dos individuos (primera mitad y segunda mitad), luego con tres individuos (primer tercio, segundo tercio y último tercio) y así sucesivamente:
Número de individuos por población: 200
Número de ciclos para mejorar cada individuo: 100
Número de ciclos del algoritmo genético: 10000
| Número de individuos(funciones) que cubren los datos | Aproximación (menor es mejor) |
|---|
| 1 | 0,297693585144862 |
| 2 | 0,225607508909792 |
| 3 | 0,0246828134882212 |
| 4 | 0,0584607494907632 |
| 5 | 0,026635890193686 |
| 6 | 0,0440122892455421 |
| 7 | 0,0203551662834108 |
| 8 | 0,0258003490308382 |
| 9 | 0,00391399470233006 |
| 10 | 0,022795774719511 |