En el anterior programa se trabajó con el tema del sobreajuste. En esta oportunidad, se elaboró un programa con interfaz gráfica para ver mejor cómo es el desempeño de una red neuronal contra un algoritmo evolutivo (se evalúan ambos procedimientos). En otras palabras, colaborar 12 es la versión gráfica de colaborar 11.
Modo de operación:
1. El botón "Generar dataset" lo que hace es generar una serie de datos de entrenamiento y una serie de datos de validación. Esos datos nacen de una función generada al azar.
2. El botón de "Procesar" lanza un hilo de ejecución que ejecuta la red neuronal y el algoritmo evolutivo. Una vez lanzado, es dejar pasar el tiempo, el programa va mostrando cuantas poblaciones va creando (algoritmo evolutivo) o cuantas redes neuronales ha creado. Entre más tiempo se deje ejecutar el programa mejor.
3. El botón "Detener" lo que hace es finalizar el proceso. No lo hace inmediatamente sino hasta que el número de poblaciones y el número de redes neuronales sean iguales y se hayan terminado de evaluar.
Una vez se detiene el proceso, se muestra por pantalla las funciones obtenidas por ambos procedimientos. Se muestra la mejor red neuronal que se ajuste a los datos de validación, sucede lo mismo con el algoritmo evolutivo.
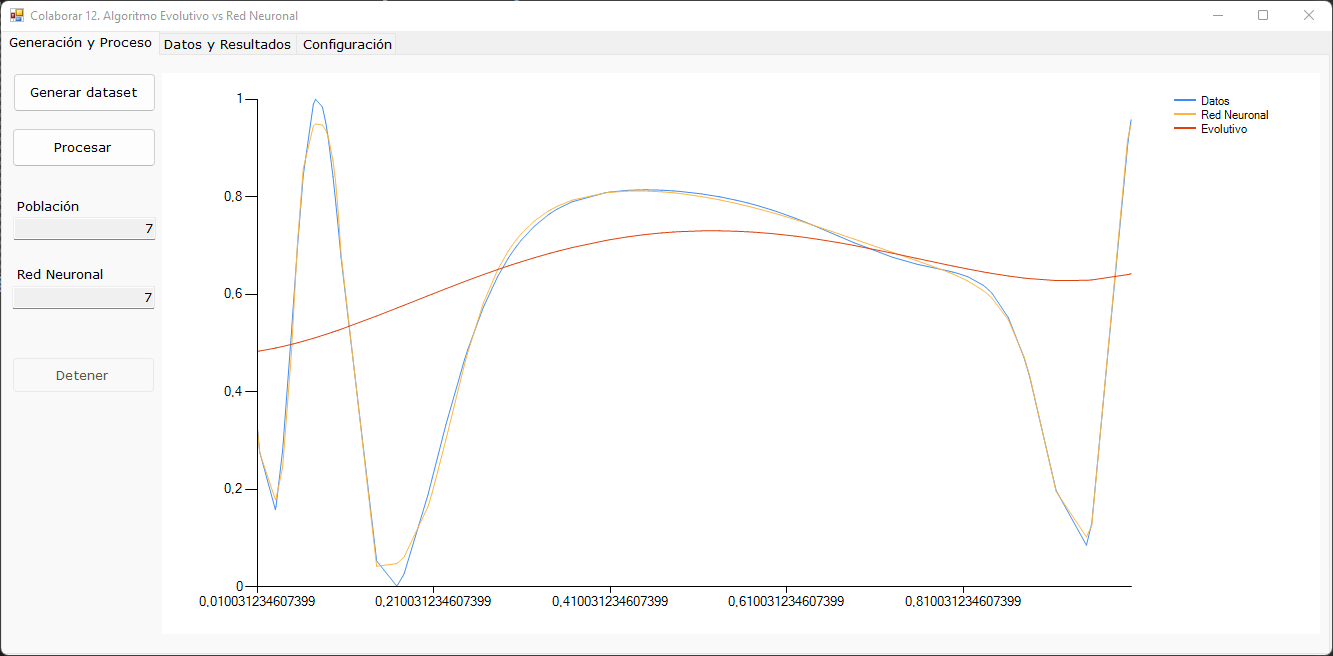
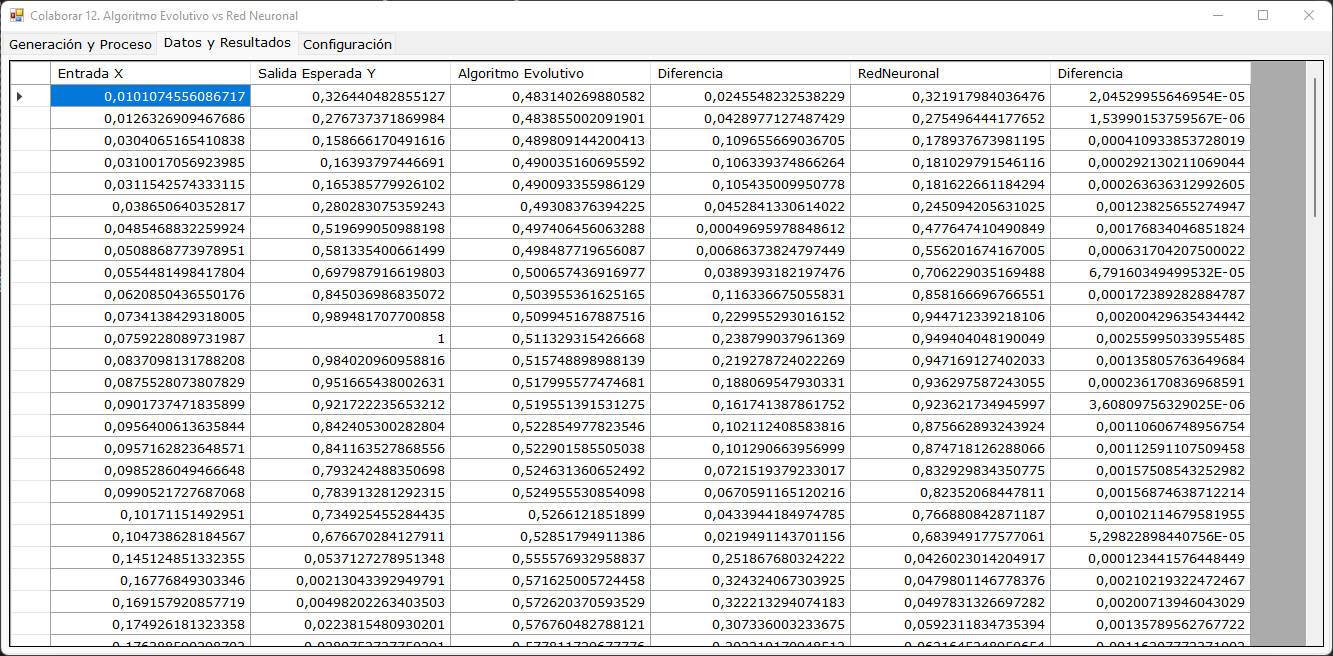
En la segunda lengüeta se muestra el dataset y cuánto sería el valor deducido por ambos procedimientos.
En la tercera lengüeta se muestra como se configura el procedimiento
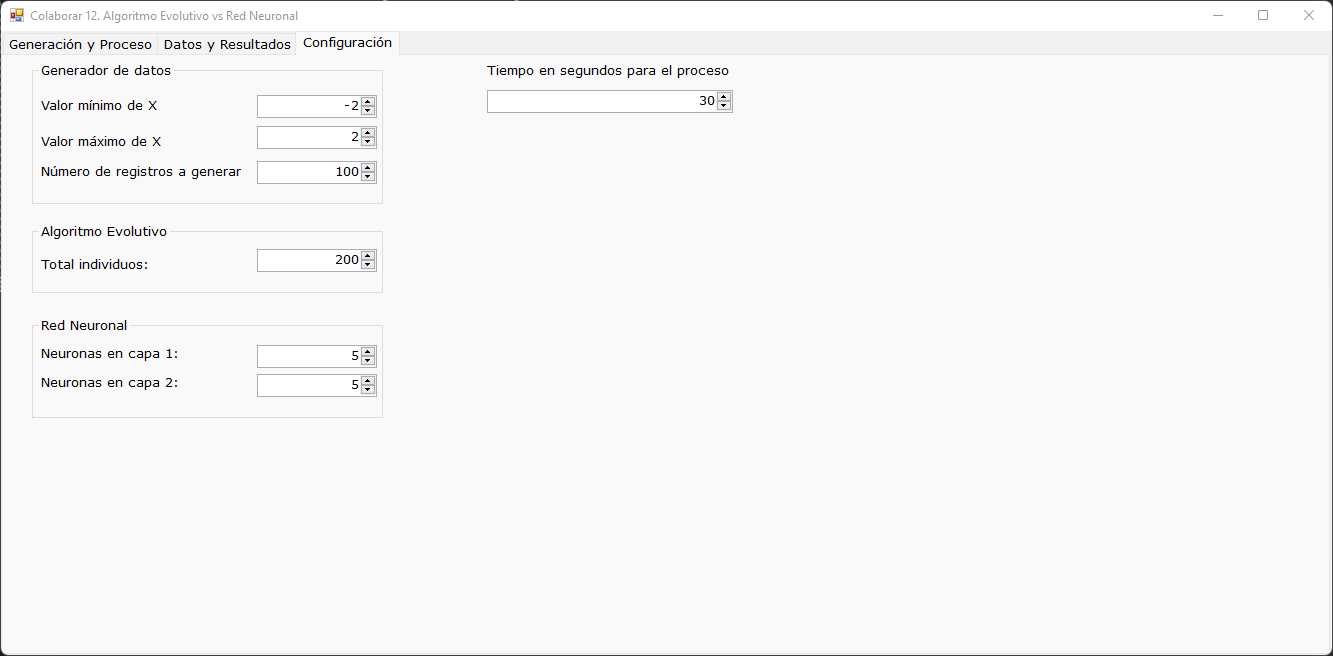
Generador de datos: es la ecuación que se genera al azar y que genera el dataset. Esa ecuación es del tipo Y=F(X). Por tal motivo se pregunta el valor de X mínimo, el valor de X máximo y el número de registros a generar. A continuación, el programa genera la ecuación al azar, de allí genera los datos tanto de entrenamiento como de validación. El programa después de generar los datos, los normaliza para que estén tanto X como Y entre 0 y 1.
Algoritmo evolutivo: ¿Cuántos individuos por población se generan?
Redes neuronales: ¿Cuántas neuronas tendrá la primera capa oculta y la segunda capa oculta?
Tiempo en segundos para el proceso: ¿Cuánto tiempo se dará a cada población generada y a cada red neuronal generada para entrenarse con los datos?
Las primeras pruebas, muestran que la red neuronal logra un mejor ajuste al dataset considerando la validación.